Chapter 3 线性学习机
3.1 本章基础知识
3.1.1 二次型的导数
假如现在有一个二次型 \(f(\boldsymbol{x})=\boldsymbol{x}^T P \boldsymbol{x}\),其中 \(P=(a_{ij})_{n\times n}\) 是一个对称阵,那么其对 \(\boldsymbol{x}\) 求导有:
\[ \frac{\partial f(\boldsymbol{x})}{\partial \boldsymbol{x}} =\left(\frac{\partial(\sum_{i=1}^n\sum_{j=1}^n a_{ij} x_i x_j)}{\partial x_i}\right)_n =2P\boldsymbol{x} \]
3.2 线性判别分析 —— Fisher 的线性判别法
先讨论一些线性可分的二分类问题:
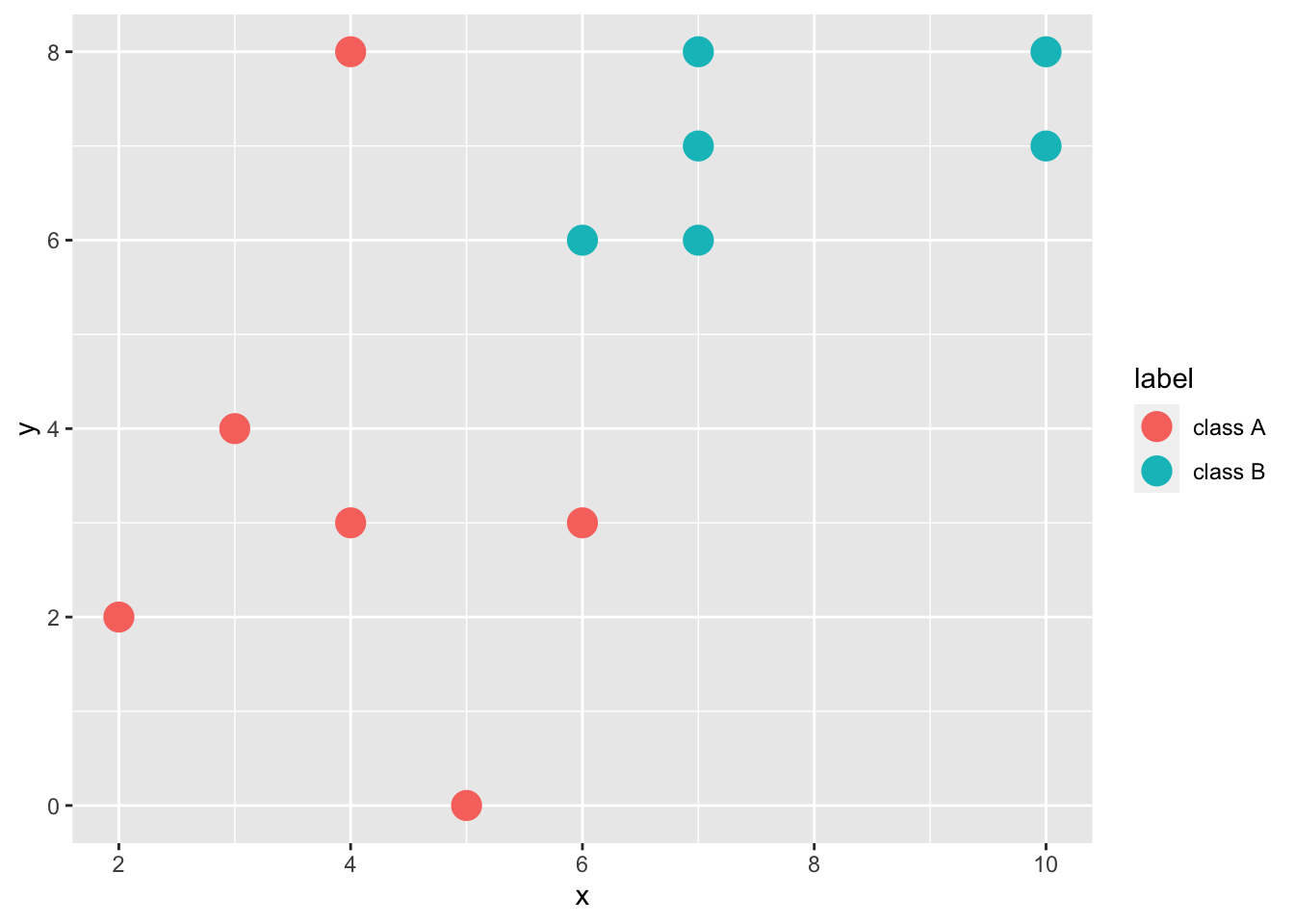
Figure 3.1: 线性可分的二分类问题
这些点显然线性可分。我们知道,一个线性判别器的形式如下:
\[ f(\boldsymbol{x})=\boldsymbol{w}^T\boldsymbol{x}+w_0 \]
其中,\(y=f(\boldsymbol{x})\in\mathbb{R}, \boldsymbol{w}, \boldsymbol{x}\in\mathbb{R}^n, w_0\in\mathbb{R}\)。
决策边界为:\(f(\boldsymbol{x})=0\),即:
\[ \begin{cases} f(\boldsymbol{x})>0\rightarrow\boldsymbol{x}\in\omega_1 \\ f(\boldsymbol{x})<0\rightarrow\boldsymbol{x}\in\omega_2 \end{cases} \]
或者使用 \(y=\text{sgn}(f(\boldsymbol{x}))=\text{sgn}(\boldsymbol{w}^T\boldsymbol{x}+w_0)\) 会更方便一点:
\[ y = \text{sgn}(f(\boldsymbol{x})) = \begin{cases} 1&\rightarrow\boldsymbol{x}\in\omega_1 \\ -1&\rightarrow\boldsymbol{x}\in\omega_2 \end{cases} \]
那问题来了,在这个例子中线性可分会存在一定的操作空间(改变 \(\boldsymbol{w}^T\) 和 \(w_0\),即调整方向和平移,这个定义我们之后再说),那么最好的判别器是什么呢?Fisher (1936) 给出了一种方法:最大化类内散度和类间散度的比值。
首先定义了这样一个映射:
\[ \mathcal{X}\rightarrow\mathcal{Y}:\quad y_i=\boldsymbol{w}^T\boldsymbol{x}_i \]
对 \(\boldsymbol{x}\) 来说,定义类内散度:
\[ \boldsymbol{S}_i=\sum_{\boldsymbol{x}_j\in \mathcal{X}_i}(\boldsymbol{x}_j-\boldsymbol{m}_i)(\boldsymbol{x}_j-\boldsymbol{m}_i)^T,\quad i=1,2 \]
其中 \(\boldsymbol{m}_i\) 是类 \(\mathcal{X}_i\) 的均值向量,\(S_i\) 表示类 \(\mathcal{X}_i\) 的类内散度。
总类内散度:
\[ \boldsymbol{S}_w=\sum S_i,\quad i=1,2 \]
类间散度:
\[ \boldsymbol{S}_b = (\boldsymbol{m}_1-\boldsymbol{m}_2)(\boldsymbol{m}_1-\boldsymbol{m}_2)^T \]
而对于 \(y=f(\boldsymbol{x})\) 来说,均值是:
\[ \tilde{m}_i=\frac{1}{N_i}\sum_{y_j\in\mathcal{Y}_i} y_j,\quad i=1,2 \]
其中 \(N_i\) 是类 \(\mathcal{Y}_i\) 的样本数,\(\tilde{m}_i\) 是类 \(\mathcal{Y}_i\) 的均值。
类内散度:
\[ \tilde{S}_i=\sum_{y_j\in\mathcal{Y}_i}(y_j-\tilde{m}_i)^2,\quad i=1,2 \]
总类内散度:
\[ \tilde{S}_w=\sum\tilde{S}_i,\quad i=1,2 \]
类间散度:
\[ \tilde{S}_b=(\tilde{m}_1-\tilde{m}_2)^2 \]
那么,Fisher 的准则就是:
\[ \max_{\boldsymbol{w}} J_{F}(\boldsymbol{w})=\frac{\tilde{S}_b}{\tilde{S}_w}=\frac{\boldsymbol{w}^T\boldsymbol{S}_b\boldsymbol{w}}{\boldsymbol{w}^T\boldsymbol{S}_w\boldsymbol{w}} \]
然后我们要解出 \(\boldsymbol{w}^\ast=\underset{\boldsymbol{w}}{\operatorname{arg\,max}}\,J_F(\boldsymbol{w})\),怎么办呢?一种办法是假设分母是常数,问题就变成了:
\[ \max \boldsymbol{w}^T\boldsymbol{S}_b\boldsymbol{w} \quad \text{s.t.}\,\boldsymbol{w}^T\boldsymbol{S}_w\boldsymbol{w}=c \]
这时候我们可以使用 Lagrange 乘子法,得到:
\[ \mathcal{L}(\boldsymbol{w},\lambda)=\boldsymbol{w}^T\boldsymbol{S}_b\boldsymbol{w}-\lambda(\boldsymbol{w}^T\boldsymbol{S}_w\boldsymbol{w}-c) \]
对 \(\boldsymbol{w}\) 求导,得到:
\[ \frac{\partial\mathcal{L}}{\partial\boldsymbol{w}}=2\boldsymbol{S}_b\boldsymbol{w}-2\lambda\boldsymbol{S}_w\boldsymbol{w} \]
令其为 \(0\),得到:
\[ \boldsymbol{S}_b\boldsymbol{w}^\ast=\lambda\boldsymbol{S}_w\boldsymbol{w}^\ast \]
即:
\[ \boldsymbol{S}_w^{-1}\boldsymbol{S}_b\boldsymbol{w}^\ast=\lambda\boldsymbol{w}^\ast \]
显然,\(\boldsymbol{w}^\ast\) 是 \(\boldsymbol{S}_b^{-1}\boldsymbol{S}_w\) 的特征向量,而 \(\lambda\) 是特征值。
然后我们再将原来的 \(\boldsymbol{S}_{b}=(\boldsymbol{m}_1-\boldsymbol{m}_2)(\boldsymbol{m}_1-\boldsymbol{m}_2)^T\) 代入,得到:
\[ \lambda\boldsymbol{w}^\ast=\boldsymbol{S}_w^{-1}(\boldsymbol{m}_1-\boldsymbol{m}_2)(\boldsymbol{m}_1-\boldsymbol{m}_2)^T\boldsymbol{w}^\ast \]
因为 \((\boldsymbol{m}_1-\boldsymbol{m}_2)^T\boldsymbol{w}^\ast\) 是标量,而我们的问题关注的是 \(\boldsymbol{w}^\ast\) 所代表的方向,那么我们可以说
\[ \boldsymbol{w}^\ast\propto\boldsymbol{S}_w^{-1}(\boldsymbol{m}_1-\boldsymbol{m}_2) \]
好了,\(\boldsymbol{w}^\ast\) 确定好了,那 \(w_0\) 怎么办呢?
一般来说,有很多种办法,比如:
\[ \begin{align} w_0&=-\frac{1}{2}(\tilde{m}_1+\tilde{m}_2),\\ w_0&=-\frac{1}{2}(\tilde{m}_1+\tilde{m}_2)+\frac{1}{N_1+N_2-2}\ln\frac{P(\omega_1)}{P(\omega_2)}, \end{align} \]
等等。